



v-for="(n, i) in 6"n从几开始,i从几开始
答:n从1开始,i从0开始
vue指令的优先级
v-cloak、v-pre
v-cloak 用于防止闪烁,在模板元素上加上v-cloak后,模板未解析完成之前,v-cloak会隐藏这个元素
1 | <template> |
v-cloak常用于应用启动阶段
v-pre
讲讲vue的directive
答:vue directive是vue的自定义指令,在Vue组件中用directives配置,全局用Vue.directive("name", options)定义,使用时用v-name:arg.foo="value"。定义时options是一个对象,在其中定义钩子函数,vue directive提供了bind、inserted、update,componentUpdated,unbind几个钩子函数,钩子函数接收4个参数,分别是指令绑定的元素el,binding对象,虚拟节点vnode,上一个虚拟节点oldVnode,其中binding对象又有以下property: 指令名字name, 传入的绑定值表达式value, 上一个表达式oldValue, 绑定值的字符串形式expression, 传入的参数arg(可用中括号语法传动态值), 传入的修饰符modifiers
vue中的scoped如何做的样式隔离,/deep/深度选择器是如何作用的
在vue单文件组件中,通过在<style>标签加上scoped属性,vue会自动将其中的样式限定在当前组件范围内,具体实现方式如下:
- 生成唯一的作用域id
- 将唯一作用域id添加到组件的每一个元素上,例如将
<div>变成<div data-v-sadfog> - 对组件内部的每个css规则,vue将其自动转换成带有唯一作用域id的属性选择器,例如将
.class{}转换成.class[data-v-sadfog]{}
在scope的作用下,带有唯一作用域id的样式选择器只作用于当前组件的样式,导致在父组件中无法直接修改子组件的样式,/deep/深度选择器(现推荐:deep()用法)
要注意的是,使用deep选择器只能向下作用到子组件内容,例如在parent.vue父组件中使用:deep(.child-class) {},在vue compiler处理过后,会是这样:deep深度选择器可能存在的性能问题:在使用deep时,vue会将其处理为全局选择器,1
[data-xxxxxxx] .child-class {}
css画一个多边形有哪些方法,不规则图形呢
答:画一个半圆可以用[[CSS 概念篇#border-radius|CSS 概念篇 > border-radius]]实现
1 | width: 100px; |
第二种方法是用[[CSS 概念篇#clip-path|CSS 概念篇 > clip-path]],使用裁剪的方式创建元素的可显示区域,不规则图形适合这种方法。
讲讲移动端适配和响应式
先理解一下这行html的作用
1 | <meta name="viewport" content="width=device-width, initial-scale=1" /> |
这是一行典型的对移动端页面适配的优化,viewport meta标记用来控制视口的大小和形状,mdn viewport meta
响应式实现方式
- rem
基于根元素的字体大小的相对尺寸单位,结合postcss将px转换为rem,但是需要借助JS根据当前屏幕尺寸来动手设置根元素的font-size值 - viewport单位 vh vw
也是通过postcss插件将px转换未vw/vh,可做到纯CSS,不需要JS - 媒体查询
- 百分比布局
tailwindcss是怎么设计响应式的
首先要记得tailwindcss的响应式设计是移动端优先,这意味着它的5个断点前缀:sm,md,lg,xl,2xl表示的是最小尺寸,或者说表示>=。未设置断点前缀的样式在所有屏幕都生效,设置了断点前缀的样式只在指定尺寸屏幕生效,例如sm:flex表示大于等于640px的屏幕上生效display:flex样式。tailwindcss的断点前缀本质上是媒体查询的语法糖,但是它很灵活,也支持自定义
tailwindcss还支持容器查询新特性
讲一讲缓存在前端页面部署上的应用
首先[[筑基🏁#缓存|筑基🏁 > 缓存]]有service worker缓存、http缓存和push缓存,
浏览器在请求资源遵循以下缓存顺序:
- Service Worker 缓存,这个过程不是自动的,需要手动编写代码注册service worker,否则浏览器的默认缓存行为不受service worker影响,service worker使用cache api或者indexDB
- http缓存
- 服务端缓存,通过网络请求资源,检查cdn中的缓存资源,没有则到源服务器去
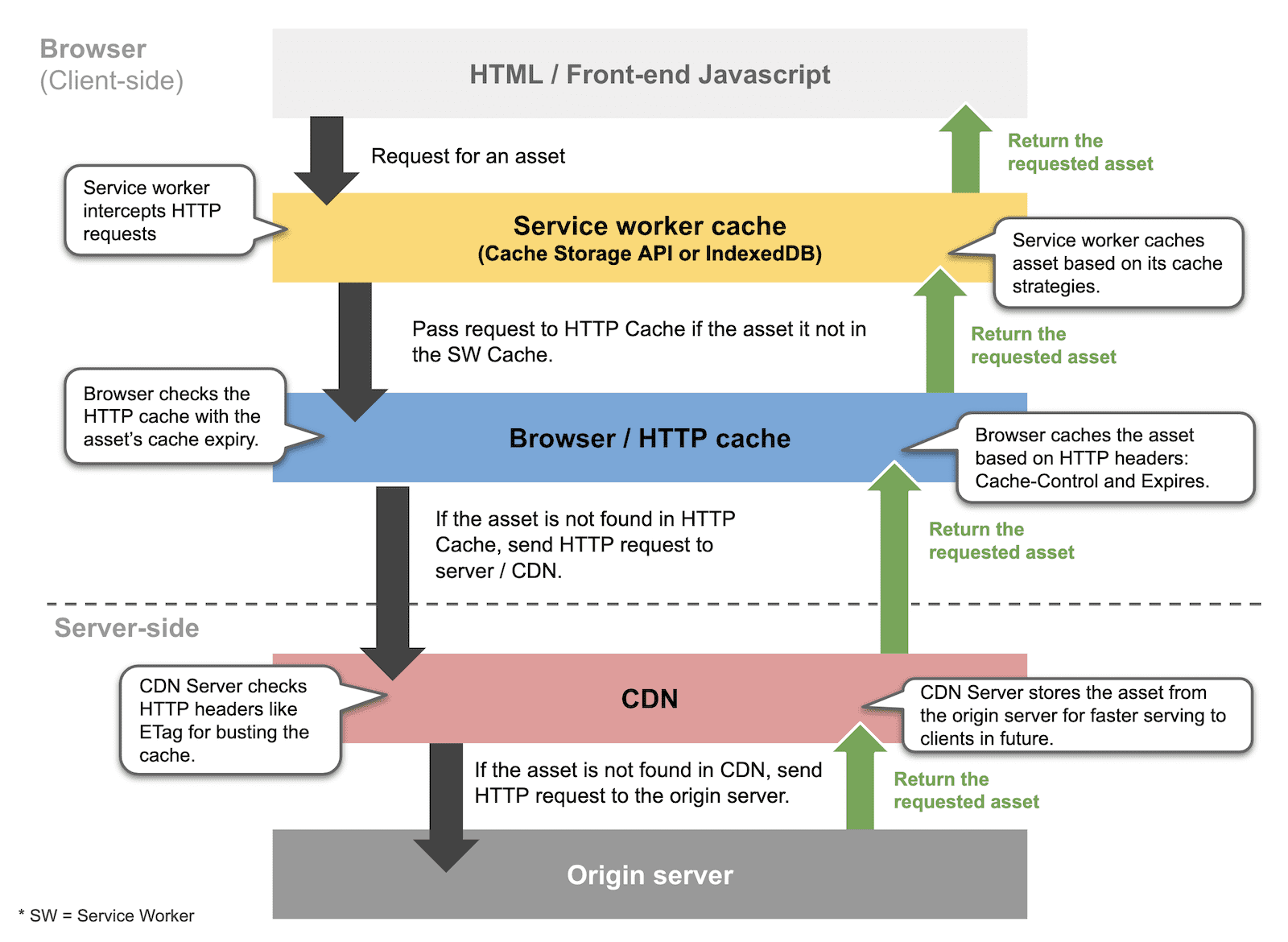
http缓存有协商缓存和强缓存,协商缓存一般用last-modified、ETag头来标识,强缓存用Cache-Control、Expires 头来标识,其中Expires因为依赖‘本地时间’存在局限性。协商缓存的内容在每次请求时仍然会向服务器发出询问,在得到缓存内容未发生变化的情况下会直接返回,我们的html doc类型文件多使用这种缓存。强缓存的内容则会设置一个过期时间,在过期时间内,不会向服务器发送询问,而是直接从memory、disk中读取缓存内容。不常更新的内容比如css、js的静态文件,图片等资源适合采用强缓存策略。
缓存的实现在浏览器中可以通过[[browser#Service Workers|browser > Service Workers]],浏览器提供了Cache Api
讲讲js中的this,绑定,以及箭头函数、匿名函数this
js中函数有普通函数、匿名函数、箭头函数。this的绑定是上下文的创建中的一步
- 普通函数function的this绑定,要看它被调用时处于的上下文,如果这个函数是作为对象的一个方法,通过对象调用,那么函数中的this指向这个对象,如果是被直接调用,那么函数中的this一般指向全局上下文。对于一个在对象中定义的function例如ff,如果直接调用ff,ff中的this是undefined
- 匿名函数的this绑定具有全局性,因此一般情况匿名函数中的this是全局对象,匿名函数的this在严格模式下是undefined
- 箭头函数的this在其被定义时就确定下来,而与其被调用时所处的上下文无关。确定箭头函数的this指向时,向上寻找最近的function,该function所处的上下文即为箭头函数的上下文
另外和this绑定相关的还有通过call、apply、bind三个函数来手动指定this
手写bind函数
bind函数参数是要指定的this,返回一个新的函数
1 | /* |
lodash 的debounce 和 throttle
讲讲CDN
CDN(content-delivery-net)内容分发网络,是一种用于加速用户访问资源速度的技术,通过将数据存储到多个地理位置分布的节点上,用户就近选择最近的cdn节点,称为边缘节点(edge node),这个阶段上缓存了源站的原始数据内容。CDN节点和源服务器之间的内容分发有 主动推送 和 被动推送 两种方式,主动推送是源服务器主动分发内容到节点,用户请求时可直接取用缓存的数据内容;被动推送是在用户访问时去向源服务器请求内容,在返回内容给用户的同时,缓存在节点服务器上。调度是CDN技术的核心,调度方式有 DNS调度(local dns出口ip)、http DNS调度(固定的dns地址)、302调度、路由调度(anycast)。OSS(object store service)对象存储服务,是一种常见的cdn源服务器类型
讲一下跨域
首先说一下什么是同源策略,同源策略是在浏览器中用于限制一个源的文档或script如何与另一个源的资源进行交互的安全策略。同源指的是协议、端口、域名三者全部相同,通过window.open()打开的about:blank页面会集成打开该地址的源。以file://加载的同一文件夹下的文件视为不同源
不同源之间的交互动作就是跨域,例如xhr和<img>标签的请求,一般来说,嵌入一个跨域资源是允许的,读取跨域资源的操作是被禁止的。<iframe>、<video>、<audio>、<img>、<script>、<link ref="stylesheet">、这些标签的嵌入是被允许的,注意只是嵌入,如果包含读取操作,则通常是不被允许的,比如用js去获取iframe内的dom,用js http请求去获取图片的二进制数据、js http跨域请求等,这些都是会被同源策略阻止的。
【注意】这里加强一下理解“为什么同源策略会重点对 读 的操作重点限制”:首先同源策略的设计重心在于“保护用户数据”,而不是“保护服务器数据”,对服务器而言,它有能力保护自己,处理写操作时会用一套安全机制比如验证、授权等来验证该请求,并且写操作通常是有迹可循的;而处理读操作时,数据已经离开服务器到了浏览器,服务器无法做别的事。所以在浏览器这边要负责起保护用户数据的功能,限制A网站不能随意读取B网站的数据。考虑以下场景:用户在A域下,想要获取B域下的一张图片并进行修改裁剪,用new Image的方式引入再绘制到canvas中处理,在读取图片像素数据(getImageData)这一步将会受到同源策略的限制。为什么限制?浏览器保护的是啥?1 保护B域的资源控制和隐私,防止B域的图片能被任意读取和修改;2 保护用户在B域的数据不被A域(恶意网站)窃取
【注】使用img标签和js请求图片数据的区别:同源策略限制的是img图片加载过程,其下载、接码和渲染全部是浏览器处理的,而用js的http请求去获取图片数据则会存在一些安全风险,因此同源策略对这两者有不同的限制
但通常情况下一个业务会有多个服务,并且处于多个不同的域下,同源策略就会阻止这些合理的请求交互,在以前开发者会用jsonp来解决跨域问题,现在是用cors来处理:客户端在发送跨域请求时,会在http header上加一个origin header来标明当前域,服务器收到请求,如果允许访问,会在响应http体中加一个Access-Control-allow-origin返回给客户端,浏览器拿到响应后检查是否有此header,有就把数据共享给客户端
如果要阻止跨域请求,主要通过cors的控制来实现。有另一种策略叫做cross-site isolation
要注意的是,cross-site isolation不是专门用于阻止跨域访问的方式,而是一个增强安全性和数据隐私的安全机制,通过设置cross-origin-opener-policy 和 cross-site-embedder-policy两种http头来实现。在启用跨域隔离后,部分类型的嵌入式资源和高级功能的可用性会受到限制。cors用于定义哪些外部来源可以访问哪些资源,而跨域隔离是为了确保加载的跨域资源的安全性
讲讲预检请求
在需要发送一个复杂http请求时,浏览器会发送一个preflight预检请求,复杂请求的定义是相对于简单请求来说的,一个简单请求满足以下所有条件:
- 使用下列方法之一:
GETHEADPOST
- 除了被用户代理自动设置的标头字段(例如
Connection、User-Agent或其他在 Fetch 规范中定义为禁用标头名称的标头),允许人为设置的字段为 Fetch 规范定义的对 CORS 安全的标头字段集合。该集合为:AcceptAccept-LanguageContent-LanguageContent-Type(需要注意额外的限制)Range(只允许简单的范围标头值 如bytes=256-或bytes=127-255)
Content-Type标头所指定的媒体类型的值仅限于下列三者之一:text/plainmultipart/form-dataapplication/x-www-form-urlencoded
- 如果请求是使用
XMLHttpRequest对象发出的,在返回的XMLHttpRequest.upload对象属性上没有注册任何事件监听器;也就是说,给定一个XMLHttpRequest实例xhr,没有调用xhr.upload.addEventListener(),以监听该上传请求。 - 请求中没有使用
ReadableStream对象。
[[|]]
浏览器会自动发送任何有必要的预检请求,请求方法是OPTIONS,请求头包含origin、access-control-request-method,服务器收到预检请求后会返回一个包含access-control-allow-origin和access-control-allow-methods请求头的response,这个response还可能包含access-control-max-age响应头来指定预检结果的缓存时间
m3u8格式 视频播放
HLS(HTTP Live Stream)是苹果推出的一种流媒体传输协议,是apple的私有协议。将音视频文件切片为多个.ts媒体文件,通过.m3u8播放列表文件进行索引,广泛用于点播和直播场景。在Apple系统中兼容性好,Safari、QuickTime等apple系统下的播放器原生支持。
一个.m3u8文件的格式通常如下:
1 | #EXTM3U m3u8标识 |
其中#EXTINF列表部分就是各个切片文件的索引
| HLS | DASH |
|---|---|
| 用ffmpeg工具处理hls视频 |
讲讲npm script
npm script执行的时候,会自动新建一个shell,在这个shell中会将node_modules/.bin子目录加入PATH变量,因此只要是.bin里有的,可以直接使用,而不必加上路径。.bin里面的脚本都做了软连接到对应的module
npm script可以使用npm的内部变量,npm_package_+变量名,可以访问package.json里面的变量,而且支持嵌套,比如对下面的package.json而言:
1 | "name": "flush", |
npm_package_version返回“1.0”,npm_package_script_install返回ins.js。
当我们import一个npm包,实际引入的是哪个文件
npm包可以分为:
- 只在客户端
browser环境下使用的 - 只在服务端
node环境使用的 browser和node环境都可以使用的
首先要了解一下package.json文件的一些配置字段,npm-doc-package.jsonexports是main选项的现代替代方案(cli version 10+),允许定义多个入口文件,支持环境之间的条件入口解析,条件包括环境变量、运行环境等。允许且只允许这里定义的内容作为入口文件main定义了npm包的入口文件,在browser和node环境下均可使用。如果用户使用require('xxx')之类的语句引入npm包,实际引入的就是main选项指定的这个文件,如果没有设置main选项,默认是根文件夹下的index.js文件module定义了npm包的esm规范的入口文件,browser和node环境均可使用,如果用esm规范引用依赖,比如import,将优先寻找module选项,其次找main选项browser定义了在browser环境下的入口文件,如果这是一个在客户端browser环境下使用的模块,应当定义此选项,而不是main选项,这能给用户提示本模块可能依赖browser环境下才有的原语,例如window对象1
2
3
4
5
6
7
8
9
10
11
12
13{
"exports": {
".": "./lib/index.js",
"./lib": "./lib/index.js",
"./lib/index": "./lib/index.js",
"./feature": "./feature/index.js",
"./feature/index": "./feature/index.js",
"./feature/index.js": "./feature/index.js",
"./package.json": "./package.json"
},
// 或者main
"main": "index.js"
}
JS模块化标准
参考文档:node文档-esm模块、node文档-commonJs模块
ESM(ES modules)
在es6中被正式引入,是一种静态引入,也支持动态引入(import()方法),导入使用import关键字,导出使用export关键字,在浏览器环境以及12以上的nodejs环境中原生支持,由于是静态导入,在js的编译过程(js虽然是一种解释型语言,但在现代js解释器中会引入即使编译JIT来优化)中就能够确定模块之间的依赖关系,因此能够做tree shaking优化。
被引入模块的代码(顶层代码:不在函数内或类内的代码)会在编译时按照依赖关系的顺序被依次执行,不同地方引入同一个模块时,模块内的代码只会被执行一次,因为js引擎会对把已经引入的模块加入缓存。
【注意】import和export语句只能在ES模块文件中使用,普通js文件不可使用,但import语句引用的内容可以是ES模块或CommonJs模块。
使用export导出内容时,有两种方式,一种是命名导出export {a},必须使用花括号括起来,import时也要用花括号;另一种是默认导出export default a,不需要花括号,import时也不用花括号;下面是一个例子
1 | // esm.mjs |
要声明一个js文件是一个模块,我们可以将它的后缀命名为.mjs,.mjs的文件目前还不能被所有的服务器正确处理,因此当服务器响应一个.mjs请求时,需要为此次响应设置content-type: text/javascript 使得浏览器能够正确处理这个文件,否则浏览器会抛出一个MIME类型错误。当我们需要在html引入一个模块文件时,需要在script标签添加属性<script type="module" src="xxx.js">以声明这是一个模块import()动态加载模块,它返回一个promise,promise结果是模块对象
CommonJs
考虑一下循环依赖的情况,例如,有两个模块,a和b,在a中有require(‘b’) 在b中有require(‘a’)。我们看看esm和commonjs分别是如何处理这种情况的:
在commonJs中,是同步导入,
import * as m from 'xxx'和import m from 'xxx'的区别
第一个使用了as是将模块内的所有导出内容全部引入(包括默认导出和命名导出),赋值到m对象上,使用时用m.default获取默认导出,m.a获取导出的a属性。
而第二个是引入xxx模块的默认导出内容,m是xxx模块中export default的内容
esm和commonjs的互相可操作性
import 语句可以引用 ES 模块或 CommonJS 模块。import 语句只允许在 ES 模块中使用,但 CommonJS 支持动态 import() 表达式来加载 ES 模块。
当使用import导入一个commonjs模块时,module.exports对象作为默认导出,命名导出可能可用,由静态分析提供
当使用require导入一个esm模块时,目前仅支持在启用 --experimental-require-module 时加载同步 ES 模块
1 | // commonjs.cjs |
.mjs vs .cjs vs .js
结合上面esm和commonJs的内容看,这三种文件后缀分别对应的是esm模块文件、commonJs模块文件、js文件
async和await的原理
生成器 generator yield
async/await借鉴了生成器函数的私信,
讲一下JS闭包
首先什么是闭包,闭包指的是那些引用了另一个函数作用域中的变量的函数。
简短表达:
闭包由函数+函数所处的词法环境组成,这个函数能够记住并访问到外层函数内声明的变量,一般是通过函数嵌套创建一个闭包。函数在创建时会获得一个词法环境([[enviroment]]属性中保存了对函数词法环境的引用),其中记录了函数能够访问的变量,函数,对象等。当出现函数嵌套函数的时候,内层函数会将外层函数的作用域链加入到自己的词法环境中,
理解闭包首先要理解函数作用域链的概念:
- 在定义一个函数时,会为他创建作用域链,保存在内部属性
[[scope]]中(在ES5+更改了概念叫[[environment]]内部属性,比scoped更复杂一些,也做了一些优化。用scoped更好理解一些,机制是一样的); - 调用一个函数时,会为这个函数创建一个执行上下文,执行上下文中有一个对象保存着函数内变量,称为词法环境;执行上下文中还有一个作用域链,作用域可以理解为一个指针列表(实际上不是一个列表,而是一种嵌套的链式引用),每个指针指向一个词法环境,链上的第一个对象是当前函数执行上下文中的词法环境(包含arguments以及其他入参),从第二个对象开始的内容则是从函数内部属性
[[scoped]]的引用
函数内部的代码访问变量时,根据变量名从作用域链中查找。函数执行完毕,函数上下文的词法环境会被销毁
以上是一般情况下函数定义和执行的情况,而闭包有所不同
在一个函数内部定义的函数会把外层函数的词法环境添加到自己的作用域链。这种情况下,外层函数在执行完毕后,他的词法环境不能被销毁,因为内层函数作用域链中仍包含对它的引用,注意:外层函数的执行上下文在执行完会被销毁,但是词法环境不会
==闭包是由函数+函数声明所在的词法环境组合成的。==
词法环境可以理解为由特定范围内可访问的变量、函数和对象组成,从结构上来说,词法环境包含两个关键内容:环境记录 + 外层词法环境的引用。
函数在创建时会同步创建一个词法环境,追踪在函数作用域内声明的变量和函数。函数在执行时会生成一个函数上下文,推入执行栈,
对闭包来说,内层函数会持有对外层函数词法环境的引用,所有即使外层函数执行完毕,它的执行上下文会被销毁,但它的词法环境仍然会保留在内层中
闭包的定义:指一个函数可以记住其外部变量,并且可以访问这些变量。在js中,所有函数是天生闭包的(new Function除外,new Function创建的函数不能访问其外层词法环境,只能访问到全局词法环境),举一个例子:
1 | function makeCounter() { |
在这个例子中,函数返回的匿名函数(暂且叫做f)f在诞生时会保存下创建它的词法环境(lexical Environment),我们每一次调用makeCounter时,都会创建一个新的词法环境,每次调用返回函数创建的词法环境是相互独立的。因为在f中有对count的引用,在f自己的词法环境中没有count,于是向外找,在makeCounter的词法环境中找到了count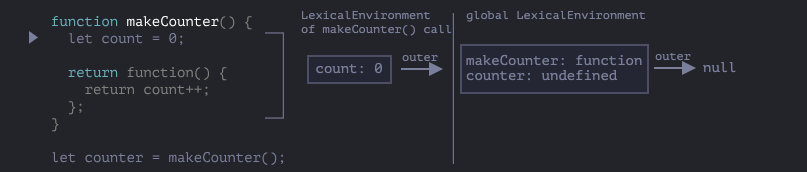

再看一个例子:
1 | const counter1 = makeCounter(); |
1 | 0 |
讲一讲JS原型链的概念
简短表达
每个函数都会有一个prototype属性,当我们通过构造函数创建一个对象实例时,实例能够通过__proto__属性访问到构造函数的prototype,所有的实例会共享prototype上的属性和方法。prototype属性本身是一个对象,那么它也会有自己的构造函数,原型对象的原型对象,这就构成一个原型链。当访问一个对象的属性或方法时,会先在只属于实例自身的属性中找,如果没找到则沿原型链往上找它的原型对象是否包含该属性,直到Object构造函数
讲一下js中的继承,有几种
==原型链继承==
实例可以访问构造函数上原型对象的属性(引用类型的属性是所有实例共享的)和方法
==构造函数继承==
在子类构造函数调用父类构造函数,通过call或apply指定this,这能解决原型链继承中属性共享的问题
==原型+构造函数组合继承==
属性通过构造函数继承,避免共享;方法通过原型链继承,可以复用
==寄生式继承==
1 | function createChild(original) { |
==寄生式组合继承==
解决组合继承中两次调用父类构造函数的问题,是ES6以前最理想的继承方式。
1 | function inherit(Child, Parent) { |
==class继承==
es6新增class和extends关键字,底层基于原型链
重绘和重排
| 重绘 repaint | 重排 reflow | |
|---|---|---|
| 定义 | 元素的视觉展示发生变化,比如背景,边框,是否可见等,浏览器重新绘制网页内容,通常发生在重排之后 | 浏览器重新计算网页某些部分的位置和几何形状,元素的重排会引起子元素和祖先元素的后续重排 |
| 触发场景 | 改变元素的背景,颜色;设置visibility: hidden; | 增加,删除,更新节点;设置display:none;修改字体大小 |
| 重排一定重绘,重绘不一定重排 | ||
【more】display:none和visibility:hidden的区别: |
||
| display:none 会完全从文档流中移除,不占据任何空间,会影响布局,其子元素也无法展示 | ||
| visibility: hidden 元素仍然占据空间,只是看不见,不影响布局,子元素默认会继承该属性,但是可覆盖 |
数据扁平化
指的是将一个多维的数组压平,转换成一个一维的数组。扁平化的好处是能够简化数据操作,便于计算和管理。JS中ES2019原生实现了flat方法用于扁平化处理数组:Array.prototype.flat(),接受一个参数,表示深度
事件委托??
利用冒泡机制,将子元素上的事件绑定到其父元素上来处理,使用场景有:有大量子元素,如果为每个子元素分别绑定事件,会消耗大量资源,这时可以考虑在父元素上绑定一次事件监听,处理所有子元素的事件,具体使用场景比如表单验证:可以交由表单父元素来处理所有表单项的验证操作
例子:
1 | <ul> |
1 | ul.onclick=function(event) { |
传递给setTimeout的回调函数的this问题
由 setTimeout() 执行的代码是从一个独立于调用 setTimeout 的函数的执行环境中调用的。如果没有在调用中指定this(比如用bind),他将默认为window
在 setTimeout 中也没有传递 thisArg 的选项,就像在 forEach() 和 reduce() 等数组方法中一样。使用 call 来设置 this 也无法指定setTimeout调用的函数的this
一旦对 setTimeout 的嵌套调用被安排了 5 次,浏览器将强制执行 4 毫秒的最小超时。
1 | let i = 10; |
讲一下 web worker
讲一下JWT
参考资料:JWT文档,JWT debugger
JSON web token,是一种开放标准,定义了一种紧凑且自包含的方式,用于在各方之间以 JSON对象的形式安全地传输信息。自包含性表示token里包含了必要的信息,不必再额外请求查询服务器
使用JWT的常用场景有:
- 认证+授权:用户登录认证完后,服务器生成一个JSON对象返回给用户,这个JSON存放在客户端,每次通信时带上这个JSON对象,服务器收到后可从中提取出用户拥有的权限;
- 信息交换:JWT可以签名,能够检验完整性和防篡改性,是安全传输信息的好方式;
JWT由3部分组成,用.隔开,格式为:xxxxx.yyyyy.zzzzz,分别表示Header Payload Signature。
==Header==
包含两个部分,token类型和签名算法,如:{"typ": "jwt", "alg": "hs256"}。
经过base64编码后得到第一部分(上面的xxxxx)。
==Payload==
声明一些数据,有3种类型的声明:
Rigistered claims预定义的声明,如iss(issuer)、exp(expire time)、sub(subject)Public claims可任意定义,推荐 IANA JSON Web Token Registry 中定义的Private claims自定义声明,用于各方之间共享数据
例如:【注】为提升紧凑性,claims的key只有3个字符1
2
3
4
5{
"sub": 123,
"name": "alice",
"role": "admin"
}
该部分数据经base64编码后得到第二部分(上面的yyyyy)
==Signature==
一个secret密钥,jwt的第三部分(上面的zzzzz)会经过以下计算步骤(假设签名算法是HS256):
1 | HMACSHA256( |
其结果是一个原始二进制签名数据,还不是一个字符串,再次进行base64编码后得到最终的signature字符串部分(上面的zzzzz)
jwt如何工作
用户登录成功后,服务端会生成并返回一个JWT字符串,客户端收到并保存起来,在发送需要验证身份的请求时,带上jwt,通常是在放在header:Authorization: Bearer <token>
json本身比较简洁,适合做为网络传输中的信息载体;大部分编程语言都实现了json解析器,这时的json用起来更简单;
服务端json解码过程:和编码过程相反,首先取出header和payload部分进行base64解码,结果是两个原始json对象。对于signature部分,其解码过程还涉及到jwt的验证环节:header和payload解码的结果按jwt编码过程-signature计算步骤做一次签名,比较签名结果和jwt signature部分是否一致
| Authentication(认证) | Authorization(授权) | |
|---|---|---|
| 你是谁?身份是否合法 | 你有什么权限? |
| validating(验证有效性) | verifying(验证安全性) | |
|---|---|---|
| 检查jwt的结构,格式和内容是否符合标准 | 检查jwt的真实性和完整性。比如签名校验,issue校验 | |
webpack.config.js 中 entry, output, module.rules, plugins 等关键配置项的作用及其具体用法
entry是代码的入口文件,可以有多个入口文件
output配置了代码打包出来的路径及文件名
module.rule定义了模块的处理规则,即对什么模块使用什么loader去处理,用于转换文件类型,如babel-loader、css-loader,每一条rule中用test项设置正则匹配文件类型,
plugins定义打包过程用到的插件,用于处理复杂任务或优化
webpack runtime
使用webpack构建项目的过程总,会有三种主要的代码类型:
- 项目源码,会有像/src、/assets等这样的文件目录结构
- 源码依赖的任何第三方的lib或者’vendor’代码
- webpack的runtime和manifest,用于管理所有模块的交互
runtime,以及伴随的 manifest 数据,主要是指:在浏览器运行过程中,webpack 用来连接模块化应用程序所需的所有代码。它包含:在模块交互时,连接模块所需的加载和解析逻辑。包括:已经加载到浏览器中的连接模块逻辑,以及尚未加载模块的延迟加载逻辑。
一旦你的应用在浏览器中以index.html文件的形式被打开,一些 bundle 和应用需要的各种资源都需要用某种方式被加载与链接起来。在经过打包、压缩、为延迟加载而拆分为细小的 chunk 这些 webpack优化之后,你精心安排的/src目录的文件结构都已经不再存在。所以 webpack 如何管理所有所需模块之间的交互呢?这就是 manifest 数据用途的由来……
当 compiler 开始执行、解析和映射应用程序时,它会保留所有模块的详细要点。这个数据集合称为 “manifest”,当完成打包并发送到浏览器时,runtime 会通过 manifest 来解析和加载模块。无论你选择哪种 模块语法,那些import或require语句现在都已经转换为__webpack_require__方法,此方法指向模块标识符(module identifier)。通过使用 manifest 中的数据,runtime 将能够检索这些标识符,找出每个标识符背后对应的模块。
有哪些性能指标
FCP First Content Paint
内容可见时间,<1.8s最佳,超过3s比较差LCP largest Content Paint
core web vitals之一,表示可见的最大图片、文本块或视频的渲染时间。时间控制在2.5s之内最佳INP Interaction to Next Paint
用户访问期间发生的所有点击、点按和键盘互动的延迟时间,最终 INP 值是观测到的最长互动时间CLS Cumulative Layout Shift 累计布局偏移
TBT Total Blocking Time 用于计算页面加载期间主线程被阻塞的时长
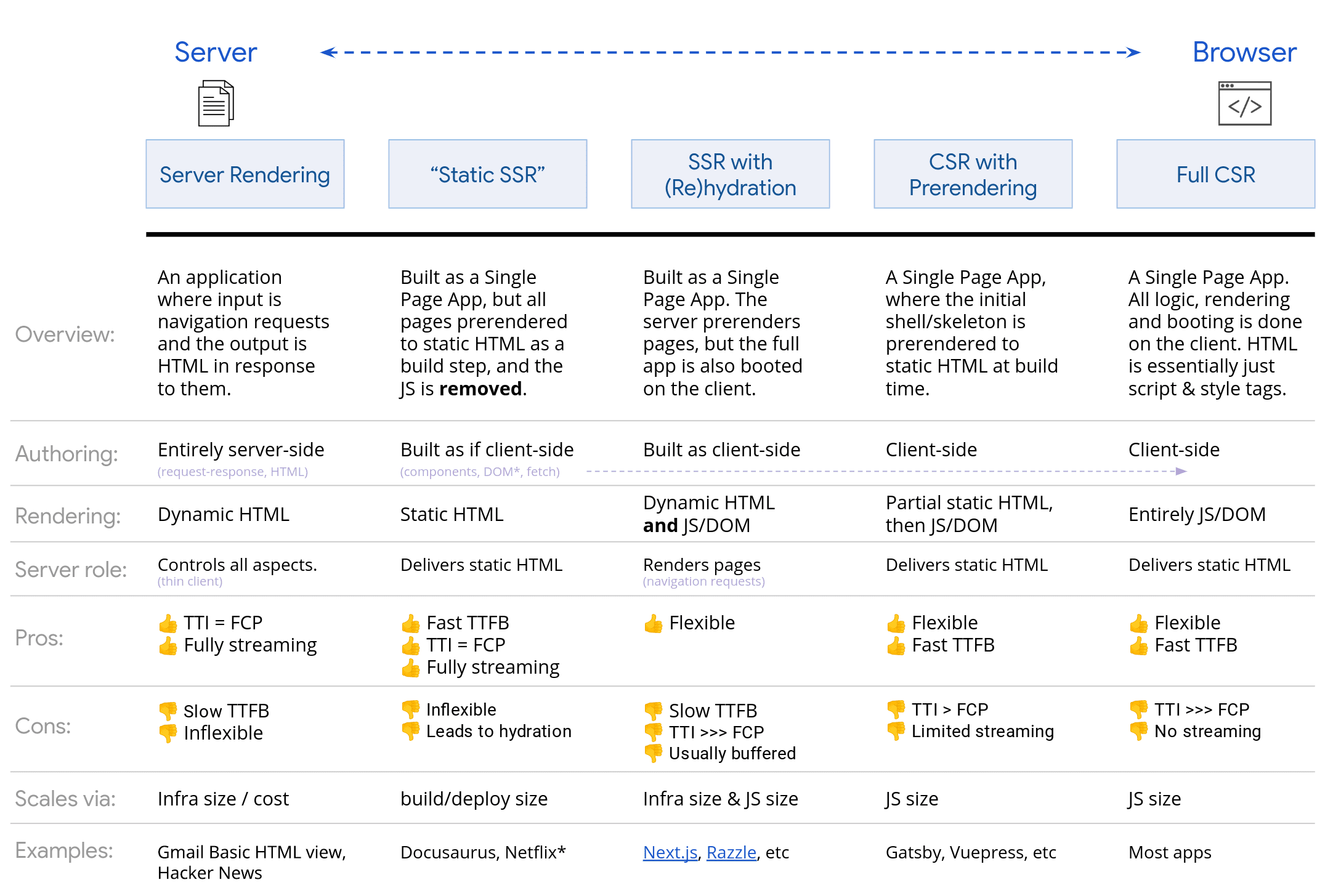
讲讲服务端渲染
在用户请求到达服务端时,服务端会为其生成一个完整的html,并减少发送到客户端的js数量,用户能够更快得看到页面内容。在服务端和客户端会分别构建一次应用,服务端构建的html到达客户端时,在js脚本执行之前,页面无法响应用户的输入
与之对应的是客户端渲染CSR,下图是从服务端到客户端渲染一个渐变的过程:
- 从最早的前后端未分离服务端渲染,比如PHP freeMarker,由后端响应请求,进行业务逻辑处理,模板渲染所有工作,返回客户端一个html页面,对每一次请求都要重新生成一个完整的html页面;
- 对于SSG,其生成的结果是一个静态的html页面,每一个路径都对应一个html,比较适用于不太变动的站点页面,因为是纯静态,同时也有较少的js安全问题
- 预渲染可以看做是SSR和CSR之间的一种渲染方式,它的特点和目标在于优化页面的初始加载速度、SEO 和用户体验。在项目构建阶段,通过静态构建的方式预先渲染一部分甚至所有页面的html静态文件,这些html文件可以在响应请求时之间提供给客户端,与SSR相比,它不用每次都实时生成页面内容,页面中变化频率较低的部分已经作为静态html于build阶段就已生成。【注】这里要注意prerender预渲染和SSG还是存在一些不同:SSG是几乎将整个站点都静态化,在构建时,几乎所有页面都能在构建时生成;而prerender则适用于特定页面的,不需要对整个站点做静态化。
- CSR则是完全在客户端做页面内容的生成,数据获取、处理、模板渲染都在客户端,通常是浏览器上完成,从服务端返回的内容是一个页面元素很少但js较多的html,因此存在交互延迟的问题
diff算法
代码分割、Tree Shaking 和懒加载等技术
Vite 开发时,如何处理 CSS 预处理器
手写Vite
手写webpack loader
热更新机制的理解
js函数的链式调用
可以通过返回一个函数来实现链式调用
eggjs VS Nuxtjs
eggjs是一个基于koa的nodejs框架,不限于前端。用这个框架得按照约定来,eggjs提出的一条原则是“约定大于配置”,我们用的其实是这个框架提供的一个vue服务端渲染解决方案
nuxtjs是一个基于vuejs的前端框架,专注于服务端渲染、静态网站生成和客户端渲染。开箱即用,能够很大简化前端开发流程。它
讲一个难点
==如何去除服务端渲染中window.__INITIAL_STATE__对象==
首先需要明白这个全局变量的作用,用户请求到达服务端,node会根据需要请求必要的数据,然后render得到一个html返回给客户端,渲染过程中用到的页面数据会被序列化嵌入到这个html的<script>中,一同到达客户端,客户端得到这部分数据可以直接使用激活html,使其可交互(即水合(hydration)过程),而无需二次请求接口,避免了页面闪烁,确保了服务端和客户端虚拟dom状态的一致性
==热力图的实现==
==js内存泄露问题,eventBus的大量使用又未销毁==
==问答的服务端渲染页面结构错乱==
==页面导出为pdf==
调研了几种方法
- 直接用浏览器提供的打印功能,能够将页面生成pdf,最简单
- HTML2pdf:传递指定元素给html2Canvas - canvas.toDataUrl - jspdf.addImage 得到一个内容是图片的pdf,实现也不复杂,可能存在的问题:有页面分割,偏移的问题
- puppeteer
1
2
3
4
5
6
7
8
9import puppeteer from 'puppeteer';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('http://xxx.net');
const pdf = await page.pdf();
await browser.close();
// 还可以截图,生成一张图像
cont screenshot = await puppeteer.screenshot(); - 后端服务

