



OSI七层模型
参考:
https://www.cloudflare.com/zh-cn/learning/ddos/glossary/open-systems-interconnection-model-osi/
https://aws.amazon.com/cn/what-is/osi-model/?nc1=h_ls
http
http1.1 vs http2 vs http3
http1.0
- 仅定义了16种状态码,默认是短连接,每一次http请求都要经历3次握手四次挥手的TCP连接
http1.1 是最早的http协议,稳定性高,兼容性好,头部信息相对较小。
- 它使用串行请求,每个请求必须等待前一个请求的响应才能进行下一个请求,存在队头阻塞问题。
- 没有cookie机制时,http协议是无状态的,这一次http请求和上一次http请求之间没有关联。
- 无加密,不安全
- http1.1不支持多路复用(真正的多路复用是从http2开始引入的),但通过引入一些技术可以模拟多路复用:keep-alive:持久连接,不必像http1.0那样每次建立tcp连接
- 引入了更多的缓存控制策略,比如e-tag、if-unmodified-since、if-match/if-none-match
- 断点续传,引入请求头range,状态码206(Partial Content)表示请求资源的部分内容
- 更多的错误状态码
http2
- 相比于http1.1的纯文本格式报文,http2采用二进制格式传输数据,
- header请求头使用encoder压缩,减少重复发送,在服务端和客户端连接时期内会保存一个“首部表”,不必每次发送所有的header,而只需发差异数据,从而降低冗余
- http2使用了多路复用的技术,同一个连接可以处理多个请求
- 服务端推送,允许服务端向客户端推送数据
http3
- QUIC(quick udp internet connections) 基于udp
cookie
为什么有cookie
因为http协议是无状态的,服务器不会记住上次和用户做了什么,引入cookie后,服务器会在返回的响应中设置set-cookie头部,set-cookie中包含sessionID,在用户这一边浏览器保存了cookie,浏览器在发起请求时带上cookie,服务器读取cookie,根据cookie识别用户身份。
域名相同,端口相同的网址可以共享cookie(不必协议相同)
cookie属性
- name:cookie名字,不可更改
- value:cookie的值
- domain:指定cookie所属域名,domain的匹配从后往前
- path:指定cookie所属路径,path和domain一起限定了cookie用于哪些URL
- expires/max-age: expire属性是http1.0中的,到了http1.1被max-age代替。expires是一个日期格式,max-age是cookie可以存在的秒数。同时指定max-age和expires时,max-age优先生效。没有指定expires或者max-age时,这个cookie是session cookie。
- secure是一个标记,标记了secure的cookie只有在https或其他安全协议下才会发送,想在网页中用js设置secure类型的cookie,必须保证协议是https的。
- httponly:设置此属性目的在于:使用js的document.cookie不能访问到此cookie,从而提供一种安全措施阻止XSS攻击。
- Samesite:是一种机制,用于定义cookie如何跨域发送,目的在于阻止CSRF(跨站请求伪造)和XSSI攻击。samesite的可选值有:lax和strict。其中strict表示禁止所有第三方的cookie,比如cookie(domain=a.com, samesite=strict),那么从其他网站访问a.com时都不会带上cookie;lax表示只有在使用危险http方法时阻止带上cookie,比如cookie(domain=a.com, samesite=lax),那么从其他网站用post方法访问a.com时不会带上此cookie。
浏览器会将cookie存储在内部数据库中,不同浏览器的存储机制不同,通常不会直接以文件的形式暴露给用户,常见浏览器cookie存储方式:
- Chrome:使用SQLite数据库存储
- Firefox:也使用SQLite存储,文件位于cookies.sqlite
- Edge:与Chrome类似,使用SQLite
- Safari:使用Plist文件或SQLite数据库存储
前端操作cookie
从前端可通过document.cookie设置和获取cookie,通过设置max-age或者expires的值来删除cookie。
cookie种类
- session cookie,只在会话期间有效,不设置expires
- persistent cookie,持久型cookie,储存在本地,设置了expires
cookie VS token VS session
因为http协议的无状态性,需要一个标记来区分不同的客户端,就有了session,session代表了客户端和服务端的一次会话过程,session中可以保存会话中的任何对象,每个session有唯一的标识符号sessionID。session保存在服务器上,这给服务器带来了负担。客户端只需要保存sessionID。在浏览器中,使用cookie的方式,sessionID通常存放在cookie中,服务端读取cookie中的sessionID,可从session列表中识别用户身份。浏览器会自动带上cookie。
session像是用户信息表,cookie是用户的通行证。
token是服务端生成的一段字符串,作为客户端请求的一个标识,称为令牌,通常是JWT,包含uid+time+sign+固定参数。uid是用户身份唯一标识,time是时间戳;sign是签名, 使用 hash/encrypt 压缩成定长的十六进制字符串,以防止第三方恶意拼接;固定参数可选。当用户首次登录后,服务端会生成一个token,用户的信息被加密存放到token中,两边都会保存好这个token,在客户端,token一般存放在localStorage、cookie或者sessionStorage中;而在服务端,token存放在数据库中?。服务端不需要保存token,JWT就是一种无状态认证。用户再次发送请求时就会带上这个token,服务器收到token后验证并解析用户身份。token需要开发者手动添加。
传递token的方法
在前端传递 token 到后端,通常有以下几种方法:
Cookie:通过设置HttpOnly的cookie,将token存储在浏览器中发送给服务器。优点是简单易用,缺点是容易受到CSRF攻击。Header Authorization:使用Authorization头将token发送给服务器,通常格式是Bearer <token>。优点是安全性高,缺点是需要额外的配置和处理,并且一旦JWT被发放,不可撤销直到过期。Query Parameter:将token通过 URL 的查询参数传递给服务器。优点是简单易用,缺点是安全性较差,容易被泄露。HTML5 Web Storage:通过localStorage或sessionStorage存储token,再通过Ajax请求发送给服务器。优点是可以在前端轻松管理token,缺点是安全性较差。
其中,推荐使用 Header Authorization 或者 Cookie 的方式,因为它们在安全性和易用性之间取得了比较好的平衡。如果需要存储用户信息等其他数据,可以考虑使用 HTML5 Web Storage。而 Query Parameter 的方式不太安全,不建议使用。
cookie/localStorage/sessionStorage
参考文档:cookie/localstorage/sessionstorage区别
通过域名可以访问网站,但只用ip不能访问,因为一个ip对应一台机器,一个机器上可能与多个网站,仅凭ip不知道要访问哪个网站,而域名进过dns解析到ip
ARP(Address Resolution Protocol)地址解析协议
http方法
HTTP 协议定义了多种请求方法,但最常用的是 GET 和 POST。这两种方法在使用和语义上有一些重要的区别:
用途:
- GET:主要用于获取(或查询)资源信息。
- POST:主要用于提交数据到指定资源。
参数传递方式:
- GET:参数在 URL 中进行传递,形式为
http://example.com?param1=value1¶m2=value2。 - POST:参数在请求体(request body)中传递,不会在 URL 中显示。
- GET:参数在 URL 中进行传递,形式为
长度限制:
- GET:由于参数在 URL 中,因此受限于 URL 的长度限制。虽然 HTTP 协议本身没有定义 URL 的长度,但是大多数浏览器和服务器对 URL 长度有限制,通常约为 2000 个字符。
- POST:理论上没有大小限制,但实际上大小可能会受到服务器的限制。
缓存:
- GET:可以被浏览器或代理服务器缓存。
- POST:默认情况下不会被缓存。
历史记录:
- GET:由于参数在 URL 中,所以会被浏览器历史记录保存。
- POST:请求数据不会保存在历史记录中。
数据类型:
- GET:只允许 ASCII 字符。
- POST:没有限制,可以发送任何类型的数据。
安全性:
- GET:由于参数在 URL 中,所以安全性较低,不适合传递敏感信息(例如密码)。
- POST:由于参数在请求体中,所以相比 GET 更安全,但仍然不应被视为完全安全的数据传输方式,因为数据默认情况下是不加密的。如果需要传输敏感信息,应该使用 HTTPS。
幂等性:
- GET:是幂等的,意味着无论请求一次还是多次,资源的状态都不会改变。
- POST:不是幂等的,每次请求都可能导致资源状态的改变。
可见性:
- GET:数据在 URL 中对所有人都是可见的。
- POST:数据不会显示在 URL 中。
这些区别的理解有助于我们更好地选择使用哪种 HTTP 方法来满足特定的需求。
常见错误提示
nginx 配置
nginx配置文件
1 | $tree /usr/local/nginx |
Nginx.conf主配置文件
1 | root@e8a4a894649f:/etc/nginx# cat nginx.conf |
子配置文件
1 | server { |
location匹配规则
1 | location 匹配规则 |
配置项
- try_files
语法:try_files [files],比如:
1 | location / { |
位于server或location块内,当匹配到此location块内时,按照指定的顺序检查文件是否存在,使用最先找到的文件响应请求。如果最后仍然找不到可用的文件,ng将返回404
http状态码
==301 move permanent==
永久地移到了新的url,新的url在location中给出,浏览器自动访问这个新的url。浏览器会缓存这个重定向关系,下次访问会跳过原url的请求,转而请求新的。和302相比减少了
一次网络请求。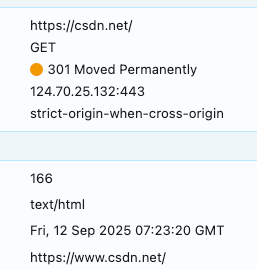

==302 ==
暂时移动到新地址,每次发送请求时,浏览器都需要向服务器询问一次,收到302响应后再重定向
==304 not modified(协商缓存)==
用户的缓存和服务器端相比没有变化,本次请求不会返回内容
域名
- ROOT 根域,一个
.,是整个域名系统的起点 - TLD(top-level-domain)顶级域名,比如
.com,.cn,.org。TLD有一个记录列表,记录了所有顶级域名 - eTLD(effective-top-level-domain)有效顶级域名,它是将TLD和某种关系绑定起来,形成一个新的顶级域名。比如github.io,它把github和.io顶级域名绑定在一起形成新的eTLD,a.github.io和b.github.io将不能共享cookie,解决了cookie共享的问题。eTLD也有自己的列表,叫Public Suffix List。通过查询PSL,就可以知道域名是否是有效顶级域名。
参考文档:TLD和eTLD的区别
查看内网出口ip
1 | # linux |
本地使用mkcert安装ssl证书
1 | lilonghui@lilonghuideMacBook-Pro ~ % mkcert -install |
1 | 测试端口是否开启,使用netcat |
http header
range表示
大文件断点续传
localhost/127.0.0.1/0.0.0.0的异同
参考文档:The Difference Between 127.0.0.1, 0.0.0.0, And localhost That Every Developer Should Know
共同点
- 这三个都是特殊ip
- 均属于A类ip地址
- 都是IPV4地址
不同
127.0.0.1
127.0.0.1属于loopback地址,所有网络号为127的ip地址都属于loopback address。
Loopback address: 所有发送到此类地址的包都会是一个回环
127.0.0.1表示本地地址,只在本地机器上有效
localhost
localhost是127.0.0.1对应的域名,可用来获取在这台机器上运行的网络服务。在大部分系统中,localhost指向IPV4中的127.0.0.1以及IPV6中的::1
0.0.0.0
在服务器上,0.0.0.0指向此机器上所有可用的IPV4地址,比如,一台机器同时拥有192.168.1.1和10.1.22.0两个ip地址,当某个服务在0.0.0.0监听时,通过这两个ip均可访问到此服务。
在路由中,0.0.0.0指向默认路由,即在路由表中未找到指定路由时的默认路由,表示目标机器不可用
如果一个主机未被分配ip,0.0.0.0指向本机
【注】当一个服务在localhost监听时,例如localhost:2233,通过0.0.0.0:2233是访问不到的;反过来,当一个服务在0.0.0.0:2233监听时,通过127.0.0.1:2233、localhost:2233、局域网ip:2233 都可以访问到这个服务
DNS协议
DNS服务器
连接网络后,如何知道dns服务器的ip地址?
最常见的是通过DHCP自动分配,DHCP(Dynamic Host Config Protocol)动态主机配置协议,这个协议用于动态地给网络(内网)中的设备分配ip,分配的过程有四个步骤(DORA)
Discover: 设备连接网络后,广播一个DHCP Discover包,询问:“有DHCP服务器吗,请返回ip和网络配置”,0.0.0.0->255.255.255.255(本地链路广播地址),子网内所有设备都将听到这个请求。值得注意的是,在收到回复之前,本设备是没有子网ip的,因此将0.0.0.0作为临时源地址,同时将本机MAC放到DHCP数据里面(如下图所示),而且数据链路层的Ethernet II也存放了源和目标设备的MAC地址

Offer:DHCP服务器(图中的172.20.52.1,通常是路由器)收到请求,回复一个offer包,其中包含:分配给请求设备的子网ip、子网掩码、网关地址、域名服务器(关键),如果返回了多个域名服务器,。发送Offer包的形式可广播可单播,广播比较通用也最兼容。
Request:设备在收到DHCP Offer包后会再次广播一个Request包,表示接收这个Offer包的配置。Request还是走广播,0.0.0.0 -> 255.255.255.255Ack:被选择的DHCP服务器收到Request包后最后发送一个ACK包,表示收到和确认本次配置
以上是一次完整的DHCP过程,另一个常见的场景是DHCP Lease Renewal租约续期。设备在经过一次完整的DORA过程后,下一次重新连接该网络,发现上次分配的ip还在有效期内(上图中可见一个IP Address Lease Time),于是简化过程跳过Discover和Offer步骤,只Request和ACK即完成
mDns 多播dns
DNS缓存
dns缓存分为os缓存和浏览器缓存,使用浏览器访问时,会优先访问浏览器缓存,未命中则访问OS缓存,最后在递归访问DNS服务器。
浏览器缓存——》OS缓存——》hosts文件——》dns服务器
浏览器缓存
浏览器DNS缓存的时间于DNS服务器返回的ttl值无关,每种浏览器会有自己的dns缓存时间
- Chrome缓存时间默认是1min,通过
chrome://net-internals/#dns可以查看各域名的dns缓存时间 - Firefox缓存时间默认1min,在
about:config首选项中搜索network.dnscache,network.dnsCacheExpiration为缓存时间、network.dnsCacheEntries为缓存条数、network.dnsCacheExpirationGracePeriod为缓存时间,等于0时表示不缓存
OS缓存
操作系统的dns缓存会参考DNS服务器的TTL值,但不完全等于。
- windows下,
ipconfig/displaydns命令展示已缓存的域名,ipconfig/flushdns清空已缓存的dns记录 - Linux下,
nscd进程负责管理dns缓存,重启nscd进程就 - macOS下,
lookupd -flushcache清空缓存
比较几个命令
| dig | nslookup | traceroute | |
|---|---|---|---|
| 用途 | 用于查询dns记录 | 用于查询dns记录 | 网络路径追踪,从源主机到目标主机的路径 |
| 输出格式 | 详细 | 简单 | 每一跳的延迟和状态 |
| 指定dns服务器 | 支持 | 支持 | |
| 适用场景 | 脚本化处理,详细的dns查询 | 快速查询dns | 网络路径诊断 |
| 协议 | DNS | DNS | ICMP TCP UDP |
SSE
http协议无法做到服务器主动推送消息,但有一种变通的方法:服务器向客户端声明,接下来要发送的是流信息,发送的不是一次性的数据包,而是一个数据流,将连续不断的发送过来。这是客户端就不会关闭链接,会一直等着服务器发新的数据流,视频就是这样的方式。可以理解为是一次用时很长的下载。
和websocket不同,sse是单向通道,从服务器到浏览器
1 | // server.js |
1 | <!-- client.html --> |
websocket
理解websocket
- 为什么有了http还需要websocket

